
BIM y big data… ya iba siendo hora de que en Especialista3D nos pronunciáramos sobre este tema que no hace más que sonar. Empecemos por el principio, ¿qué es el Big data del que todo el mundo está hablando? y aquí hay que recurrir a la RAE.
¿Qué es el BIG data?
Ahí va la definición según la RAE del Big Data: «Conjunto de técnicas que permiten analizar, procesar y gestionar conjuntos de datos extremadamente grandes que pueden ser analizados informáticamente para revelar patrones, tendencias y asociaciones, especialmente en relación con la conducta humana y las interacciones de los usuarios.»
Ok, traducimos. El big data son las técnicas para analizar conjuntos de datos extremadamente grandes. Vale, ¿y qué se considera «extremadamente grande»? En este caso ese extremo no lo define la cantidad de datos aglomerados. Tú podrías pensar «a partir de 10 Gb» es big data. Pero te digo una cosa: puedes llenar una matriz con diez millones de celdas sólo con CEROS, y con esa tabla te garantizo dos cosas:
- Ocupará 10 Gb.
- Nadie podrá sacar ninguna conclusión de esa información.

Por tanto este conjunto de datos tiene que ser lo suficientemente grande, ser datos DE CALIDAD y bien organizados como para poder sacar conclusiones de las relaciones que los datos tienen entre sí. Cuanta mayor sea la cantidad y calidad de datos mayores serán las conclusiones que podemos extraer de los mismos.
Ahora mismo hay muchísimo hype por el «big data». Este hype no viene de «qué emoción, ahora puedo almacenar diez millones de datos inútiles», sino de «con 10 millones de datos de X tal vez pueda deducir Y.
¿Dónde vemos big data en nuestro día a día, quién hace big data hoy?
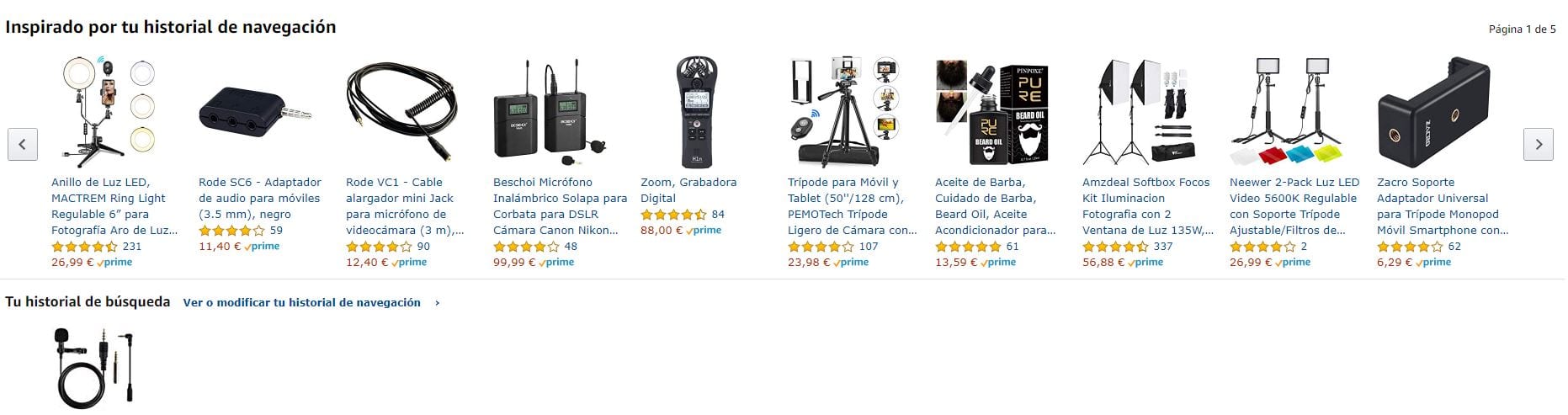
Voy a ponerte un ejemplo de Big Data en el día a día. Esta es la imagen que amazon tiene para mi usuario como «inspirado según mi historial de navegación». Según leo esto no puedo evitar reirme internamente, ¿cómo es capaz amazon de inspirarse TANTO con un solo objeto que he buscado? (mira la imagen de abajo).Por suerte para Amazon yo no soy su único usuario, se arruinarían si así fuera. Amazon cruza la información de millones de usuarios de todo el mundo para poder «inspirar» mi búsqueda y ofrecerme objetos relacionados con la misma. Es más, lo más seguro es que los usuarios que compraron el micro que yo también compré han comprado también los cachivaches de arriba.
Para poder hacer estas deducciones Amazon no solo tiene que tener la información de estos millones de compras sino que además tiene que tener todas estas compras ordenadas con el mismo criterio y cruzar esta información entre sí.
Ok, ¿qué tiene que ver todo esto con las metodologías BIM?
En los modelos BIM introducimos muchísima información, de eso no cabe duda. Ahora bien, ¿es esta información suficiente para poder utilizar sobre ella técnicas de Big data? Vamos a analizar lo que hemos dicho antes. Para poder utilizar estas técnicas la información debe:
- Estar ordenada.
- Ser correcta.
- Estar suficientemente caracterizada como para poder obtener conclusiones de las relaciones de esta información entre sí.
- Ser suficientemente abundante como para poder aplicar las técnicas del big data.
Estos cuatro puntos son fundamentales, sin una información ordenada no es que no podamos hacer «big data» de un modelo bim. Es que no podremos obtener una tabla de planificación decente, no podremos obtener mediciones, olvídate de sacar un presupuesto y hasta de organizar unos planos dignos.
Me voy a centrar en los dos primeros conceptos solamente, orden y corrección de los datos, porque en este momento llevo ya casi 600 palabras de artículo. Si quieres que profundice en los otros dos deja un comentario en este artículo.
Información ordenada y correcta en modelos BIM
Llegamos al punto conflictivo del asunto. Es precioso llenarnos la boca del «big data en BIM» y de las «enormes bases de datos» pero la realidad es que para poder hacer esto es necesario dos pasos previos:
Paso 1: Poblar a las categorías, tipos, elementos de información.
Alguien (un ser humano habitualmente) tiene que:
- Deducir para qué quiere un modelo y para qué quiere información en dicho modelo.
- Pensar qué información debe introducirse en el modelo según el uso de la información, el «para qué».
- Poblar el/los modelo/os de parámetros en los que introducir dicha información.
- Rellenar los parámetros con la información, bien de forma manual o bien de forma automatizada.
- Si los parámetros se completan de forma manual esta acción llevará muchísimas horas de los seres humanos encargados de completarla y puede tener múltiples errores.
- Si se rellenan de forma automática estos seres humanos tendrán que hacer un dynamo, o un script o usar una aplicación X que complete esta información.
Y tú me puedes decir: oye pero, ¿y si vuelco la información desde una base de datos fiable, como la de catastro? Ay amigo… qué pocas bases de datos fiables existen hoy en día.
Suerte limpiando y trabajando con este tipo de bases de datos. Te dejo aquí un ejemplo que un compañero ha mostrado hace poquito, de lo que tuvo que hacer para poder trabajar con la base de datos de catastro.
Paso 2: corregir los errores de la información
Incluso si el paso 1 se hiciera perfecto habría que comprobar que toda la información que hemos introducido en el/los modelos es correcta. Hay otro punto que puede complicar esta operación de la corrección de la información: que estemos trabajando en múltiples modelos o con modelos en distintas fases.
En este caso la cosa se complica: ¿cómo comprobar que la información es coherente en todos los modelos?
Un ejemplo claro de este caso es cuando trabajamos con un modelo exclusivo para la planificación. En este caso es muy frecuente que se trabaje en paralelo con 2 modelos:
- El modelo nativo: en revit, archicad, aecosim o lo que utilicemos para modelar.
- El modelo de planificación 4D, en el ejemplo está en Synchro.
Este es el ejemplo del vídeo. En él Viero enseña un sistema muy sencillo para chaquear la información que viene de 2 modelos diferentes. La gran pregunta aquí puede ser, ¿y cómo sabe que el elemento es el mismo viniendo de 2 modelos distintos?
Primero te voy a dejar con el vídeo:
Si te fijas Viero durante todo el vídeo trabaja con 2 o 3 columnas que le sirven para identificar los objetos, los ids de los objetos. Ya te adelanto que estos ids en las tablas de Revit no aparecen por defecto, para sacar estos ids hay que tirar de sistemas como por ejemplo dynamo. Viero vuelca siempre a Synchro varias formas de identificar los objetos para mantener siempre la relación entre ambos programas y sus elementos.
Sobre este punto me quedo aquí en el desarrollo porque Viero habla largo y tendido sobre cómo conservar esta información de los objetos en Gestión de Obra con BIM.
En este caso Viero corrige y gestiona la información de los modelos desde Google Sheets, ¡y esto te va a ser perfectamente válido en el 70% de los casos! Si los modelos BIM y la información empiezan a ser muy muy muy muy grandes entonces, y solo entonces, nos plantearíamos trabajar con bases de datos o con data frames.
Conclusión para queridos amigos, bimfluencers, gurús y quien quiera escuchar sobre bim y big data
Mi point aquí es que sí, es motivador hablar de big data y BIM, pero completamente inútil hasta que no tengamos los fundamentos atados a la hora de crear, volcar y gestionar la información.
Hay profesionales que empiezan a pensar que con tener modelos BIM ya pueden hacer big data: no, nope, nicht, rien de rien, nanimo, no way in hell,… ¡QUE NO HOMBRE, QUE NO!
Si quieres hacer big data con tus modelos más te vale que tengas un criterio uniforme para introducir los parámetros y su información en los modelos. Además, ¡dales muchos mimos y amor a todos los profesionales que introducen dicha información en los modelos y comunícales bien los estándares y protocolos! Algunos de los protocolos de control podrían parecerse a los que enseña Viero en el vídeo, para corregir posibles errores en la información.
Nos encantaría conocer tu experiencia con la gestión de parámetros y el control de la calidad de la información. ¡Ponla en los comentarios!
![]() ¿BIM y big data? Sin esto NO por Especialista3D está licenciado bajo una Licencia Creative Commons Atribución-NoComercial 4.0 Internacional.
¿BIM y big data? Sin esto NO por Especialista3D está licenciado bajo una Licencia Creative Commons Atribución-NoComercial 4.0 Internacional.